
What is Enterprise ML?
What does it take to deliver a machine learning (ML) application that provides real business value to your company?
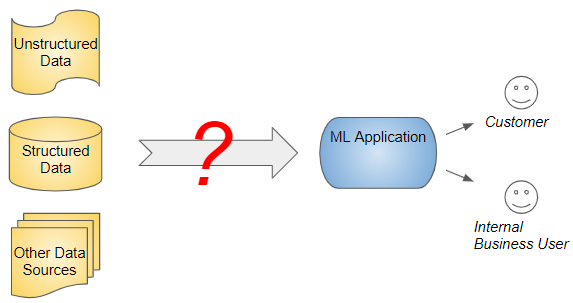 Deliver business value through ML applications in the enterprise (Image by Author)
Deliver business value through ML applications in the enterprise (Image by Author)
Once you’ve done that and proved the substantial benefit that ML can bring to the company, how do you expand that effort to additional use cases, and really start to fulfill the promise of ML?
And then, how do you scale up ML across the organization and streamline the ML development and delivery process to standardize ML initiatives, share and reuse work and iterate quickly?
What are the best practices that some of the world’s leading tech companies have adopted?
Over a series of articles, my goal is to explore these fascinating questions and understand the challenges and learnings along the way.
- How does one train an ML model in the “real world”, and how is that different from building an ML prototype “in the lab”?
- How do you take that model to production and keep it running at peak performance month after month?
- What infrastructure, system architecture, and tooling have been put in place by companies that are at the forefront of this trend?
- How do you build data pipelines to extract value from the vast amount of data collected at your company and make it available for your ML and Analytics use cases?
In this first article, we will dive deeper into the crucial step of building and training an ML model, because that sits at the heart of this process.
In order to do that, let’s first set the context and get a high-level overview of an organization’s overall ML journey.
Maturing along the ML journey
Let’s say a company has gathered a rich set of data and wants to make use of machine learning so that it noticeably improves the experience of its customers or impacts its business operations in a major way.
Typically, most companies that are able to successfully leverage ML go through various stages of maturity.
 An organization goes through stages of ML maturity (Image by Author)
An organization goes through stages of ML maturity (Image by Author)
- Starting Out - Identify a problem and define the business objectives. Start R&D activity to develop an ML model.
- Pilot - First model trained. Application ready in production.
- Early-stage - Handful of models in production for a year or two.
- Intermediate stage - Several models in production for a variety of business scenarios across multiple departments.
- Advanced - Agile ML application development, standardized tools, and processes for quick experimentation and delivery.
But this is a hard road to follow. Many companies get stuck at the very first stage and are not able to extract tangible business value from their ML investments.
Now that we’ve talked about the long-term journey at a high level, let’s narrow in on a single ML project along this path, and look at the steps involved end-to-end.
ML Application Lifecycle and Roles
Delivering an ML application involves several tasks. Over the last few years, a number of specialized roles have cropped up in the industry to perform these tasks.
Note that this area is still evolving and that this terminology is not standard. If you went to a few different companies and asked them about these tasks and these roles you’ll probably get slightly different interpretations. The boundary between these roles is somewhat fuzzy. In some cases, the same person might perform all of these responsibilities.
However, some of these concepts are starting to crystallize. So it is still useful for us to get a broad sense of the process.
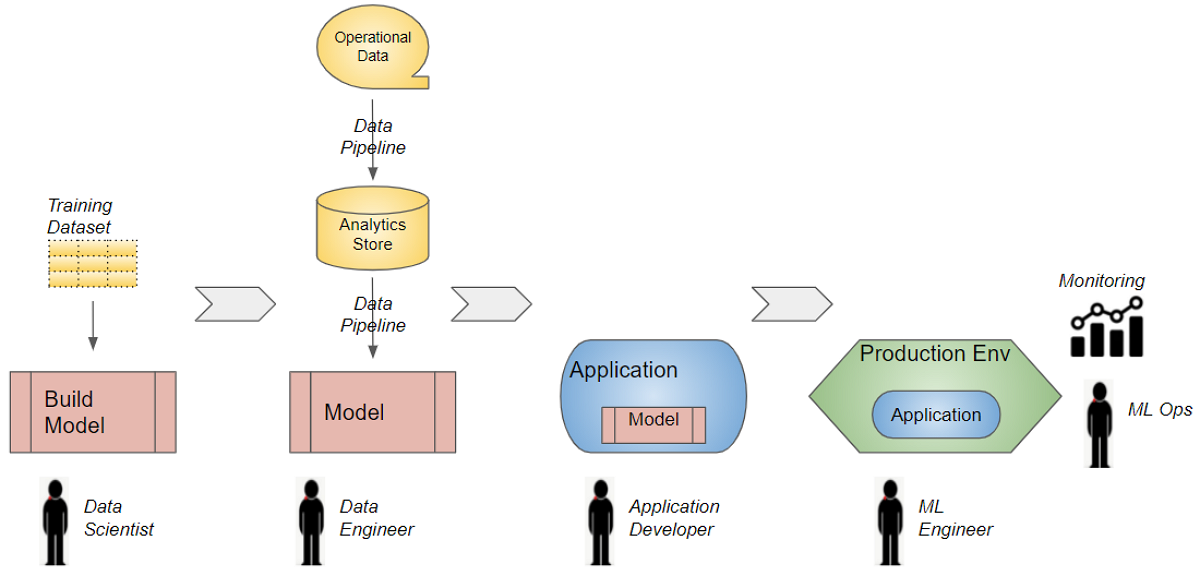 ML Application Lifecycle (Image by Author)
ML Application Lifecycle (Image by Author)
- The process starts with the Data Scientist building and training a model, often using a snapshot of the training data.
- The Data Engineer then sets up the data pipeline to fetch the training data from the company’s Analytics store. The pipeline might also populate the Analytics store from the operational data sources.
- The trained model then has to be integrated with the business application that is used by end-users. It obtains the input data that the model consumes to make its predictions. The predicted results are then presented back to the end-users. This is done by the Application Developer or Product Engineer.
- The ML Engineer deploys the ML application into production.
- Finally, ML Ops is responsible for keeping the application running in production and monitoring its performance.
As we just saw, the first stage in the application lifecycle is to build and train the ML model. This is often the most “glamorous” and most technically challenging part of the project. Let’s zoom in to see what it involves.
How is training a “real world” ML model different from a “demo” ML project?
There is no shortage of resources, tutorials, online courses, and projects on the Internet that cover every possible technical aspect of building a machine learning or deep learning model for a range of applications. However, the majority of them cover building ML models in a very controlled “demo” environment.
How does that differ from what you will encounter in the “real world”? By far the biggest difference has to do with access to a labeled dataset. Demo projects invariably start with a carefully curated dataset that has already been prepared for you. The data is already cleaned and systematically labeled. The problem is neatly bounded because the fields in the dataset have been selected and scoped.
In a real project, on the other hand, you start with a blank slate. Preparing your dataset becomes one of the most demanding aspects of the project. You have to tackle a number of tricky issues:
- What data sources are available?
- How do we query and extract the data?
- What fields do they contain?
- What data features will we use?
- How do we get labels?
- Is the data formatted properly?
- Are there missing values or garbage values?
- What data slices/segments should we use?
- How much training data do I need?
- How can I augment my data?
Secondly, in a demo project, the emphasis is often on squeezing out every last drop of accuracy for your model, or to get state-of-the-art results. In many online competitions, a difference in the metric score between 79.0345 and 79.0312 can mean hundreds of ranks on the leaderboard.
In a real-world project, spending a few more weeks to obtain an improvement of the metric by a percent or two, may not be worth it. The accuracy of your model is probably only one factor in the overall business outcome. It is often far more important to deliver a working solution quickly, with a noticeable customer improvement, get feedback and iterate quickly.
Model Building and Training Workflow
Let’s say that the problem to be solved and the business objective is clear, and you have an initial hypothesis for how to tackle it. Typically, there are several steps involved in creating your ML model, that are performed by a Data Scientist or a team of Data Scientists.
 ML Model Workflow (Image by Author)
ML Model Workflow (Image by Author)
- Data Discovery: You might start by browsing your data sources to discover the data set you want to use. Importantly you also need to identify what data will be used as the target labels.
- Data Cleaning: The data is probably messy and requires verification and cleaning. There might be missing or invalid values, outliers, duplicates, and so on. Some fields might have useless values eg. A field like “Churn Reason” has a lot of values that simply say “Unknown”. Some values may not be formatted correctly eg. numbers, dates. If you’re dealing with images, you might have blurry pictures, images of different sizes and resolutions, inadequate lighting, or photos taken from odd angles.
- Exploratory data analysis (EDA): Look at the data distributions to identify patterns and relationships between the fields. You might identify seasonal trends or slice the data into relevant segments etc.
- Feature Engineering: Derive new features by enriching some fields, performing aggregates or rollups, or doing calculations by combining multiple fields. For instance, you might use a date field to extract new features for the number of days since the beginning of the month or year, or whether it is a holiday.
- Feature Selection: Identify the features that are most useful to the model for predicting results. Remove features that add no value to the model.
- Model Selection: You might try out several different machine learning algorithms or deep learning architectures, to find the one with the best performance.
- Hyperparameter Tuning: For each model, there are several hyperparameter values to be optimized eg. the number of hidden layers and sizes of each layer in a neural network.
- Model Training: Pick a model, select some data features, try some hyperparameters and train the model.
- Model Evaluation: Test the model against the validation data set. Track and compare the metrics for each model.
- Inference: After a promising potential model has been identified (along with features and hyperparameters), build the logic to make predictions on unseen data.
- Repeat, repeat, and repeat again: Change something, try a different idea, and keep doing this many, many times till you find something that works well.
It is imperative that you keep meticulous notes to track each of your trials, the data features and hyperparameters that were used, and the metrics that were obtained. That will help you to go back and identify promising models for further investigation, and to be able to re-run tests and reproduce results.
Model Building Challenges
Building an ML model is tough. The work is very researchy and iterative and requires a lot of experimental trial and error.
Unlike most software development projects, where you know how to solve the problem at hand, an ML project has a lot of uncertainty and unknowns. In the beginning, you may not know what the solution is, whether it is even feasible or how long it might take. Estimating and planning timelines involves a fair amount of guesswork.
Often, ML models are black-boxes. When a model fails to produce the desired results you might not be sure exactly why it failed. In many cases, the fix is to simply propose another hypothesis or try something different, and hope that it improves performance.
Finally, the model is ready! Now the hard work really begins…
After several weeks or months of work, you finally solve the problem and have a model that is performing well in a development setting.
However, as we will see in the next phase, this is only a very small part of the way to your destination. Bigger challenges and pitfalls lie ahead.
Model development is usually done in Jupyter notebooks by a Data Scientist or a team of Data Scientists. It is likely that the model is trained using a static snapshot of the dataset in CSV or Excel files. Training is run on the developer’s local laptop, or perhaps on a VM in the cloud.
In other words, the development of the model is fairly standalone and isolated from the company’s application and data pipelines. The hard work of integrating the model and deploying it in the production environment is about to begin…
Conclusion
As we’ve just seen, Enterprise ML is a journey, and like all journeys, it begins with a first step, that of building your ML model. In many ways, this part is both technically complex and exciting.
However, it is not this stage, but the next one that often trips up many projects and prevents them from seeing the light of day. Now that we have a sense of the “Model Building” phase, we are ready to look at the “Putting the Model Into Production” phase in the next article.
And finally, if you liked this article, you might also enjoy my other series on Transformers as well as Audio Deep Learning.