
Generating Image Captions using deep learning has produced remarkable results in recent years. One of the most widely-used architectures was presented in the Show, Attend and Tell paper.
The innovation that it introduced was to apply Attention, which has seen much success in the world of NLP, to the Image Caption problem. Attention helped the model focus on the most relevant portion of the image as it generated each word of the caption.
In this article, we will walk through a simple demo application to understand how this architecture works in detail.
I have another article that provides an overview of many popular Image Caption architectures. It provides the background about the main components used by these architectures, explains the unique characteristics of each architecture and why they are interesting. I encourage you to take a look if you’re interested.
Image Captioning Application
An Image Captioning application takes an image as input and produces a short textual summary describing the content of the photo.
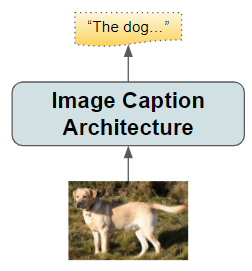 (Image by Author)
(Image by Author)
For our application, we start with image files as input and extract their essential features in a compact encoded representation. We will input these to a Sequence Decoder, consisting of several LSTM layers, which will decode the encoded image and predict a sequence of words that describes the photo.
 (Image by Author)
(Image by Author)
As for most deep learning problems, we will follow these steps:
 (Image by Author)
(Image by Author)
Image Caption Dataset
There are some well-known datasets that are commonly used for this type of problem. These datasets contain a set of image files and a text file that maps each image file to one or more captions. Each caption is a sentence of words in a language.
For our demo, we will use the Flickr8K dataset (images, text). This is a reasonably sized dataset that contains about 8000 images, which is sufficient to train our model without requiring a huge amount of RAM and disk space.
After downloading this to a ‘dataset’ folder, we see that it consists of three parts:
- Image files in the ‘Flicker8k_Dataset’ folder: This folder contains roughly 8000 .jpg files eg. ‘1000268201_693b08cb0e.jpg’
- Captions in the ‘Flickr8k.token.txt’ file in the main folder: It contains captions for all the images. Because the same image can be described in many different ways, there are 5 captions per image.
- List of Training, Validation, and Test Images in a set of .txt files in the main folder: ‘Flickr_8k.trainImages.txt’ contains the list of image file names to be used for training. Similarly, there are files for validation and test.
Explore the Data
Each line in the Captions file represents one caption. It contains two columns separated by a Tab. The format of each line is:
“<image file>#i <caption>”, where 0≤i≤4 for each of the 5 captions eg. “1000268201_693b08cb0e.jpg#1 A girl going into a wooden building .”
Here is what one image with its five captions looks like:

Training data pipeline
We will build the pipeline for our deep learning architecture in two phases.
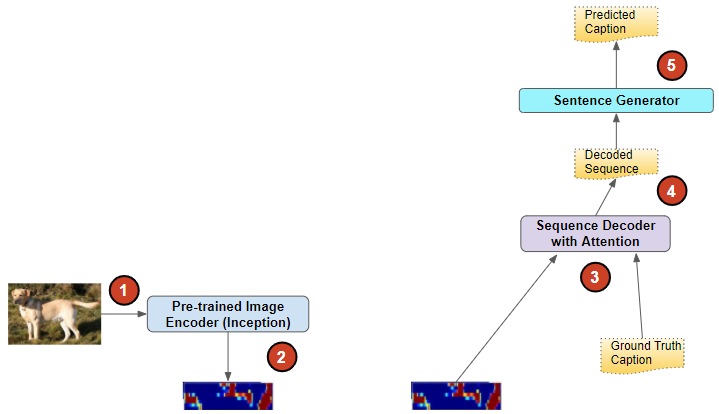 (Image by Author)
(Image by Author)
- For the first phase, we use transfer learning to pre-process the raw images with a pre-trained CNN-based network. This takes the images as input and produces the encoded image vectors that capture the essential features of the image. We do not need to train this network further.
- We then input these encoded image features, rather than the raw images themselves, to our Image Caption model. We also pass in the target captions corresponding to each encoded image. The model decodes the image features and learns to predict captions that match the target captions.
For the Image Caption model, the training data consists of:
- The features (X) are the encoded feature vectors
- The target labels (y) are the captions
To prepare the training data in this format, we will use the following steps:
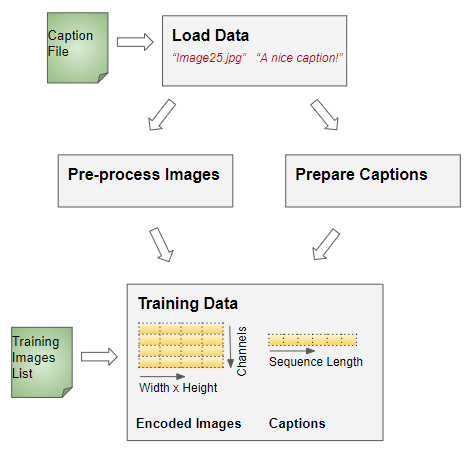 (Image by Author)
(Image by Author)
- Load the Image and Caption data
- Pre-process Images
- Pre-process Captions
- Prepare the Training Data using the Pre-processed Images and Captions
Now, let’s go through these steps in more detail.
Load Images and Captions
Let’s load the full dataset into a Python dictionary:
 (Image by Author)
(Image by Author)
Then use the Training List text file to select the subset of images to be used for training from our full dataset.
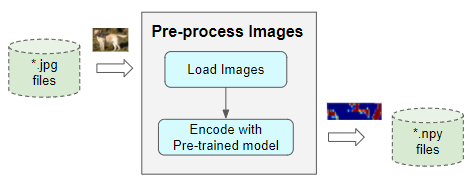
Pre-process Images
We will use a pre-trained Inception model which is a well-known Image Classification model with excellent performance. This model consists of two sections:
- The first section consists of a sequence of CNN layers that progressively extract the relevant features from the image to produce a compact feature map representation.
- The second section is the Classifier that consists of a sequence of Linear layers. It takes the image feature map and predicts a class (eg. dog, car, house, etc) to which the feature belongs.
For our Image Caption model, we need only the image feature maps, and do not need the Classifier.
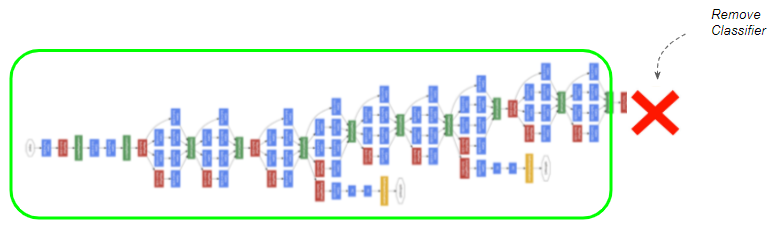 (Image by Author)
(Image by Author)
We download this pre-trained model, truncate the Classifier section and encode the training images. The model returns a vector of shape (8, 8, 2048), which we reshape to (64, 2048).
The features for each encoded image are saved in a separate file using the image name and another extension eg. ‘1000268201_693b08cb0e.npy’
 (Image by Author)
(Image by Author)
Now that the images are ready for training, we have to prepare the captions data next.
Prepare Captions
Each caption consists of an English sentence. To prepare this for training, we perform the following steps on each sentence:
 (Image by Author)
(Image by Author)
- Clean it by converting all words to lower case and removing punctuation, words with numbers and short words with a single character.
- Add ‘<startseq>’ and ‘<endseq>’ tokens at the beginning and end of the sentence.
- Tokenize the sentence by mapping each word to a numeric word ID. It does this by building a vocabulary of all the words that occur in the set of captions.
- Extend each sentence to the same length by appending padding tokens. This is needed because the model expects every data sample to have the same fixed length.
Prepare Training Data using a Tensorflow Dataset
We now have pre-processed images and captions. We go through every training image and its matching captions to prepare the training data. This consists of:
- Features (X) consisting of the image file paths
- Targets (y) consisting of the cleaned and tokenized captions
We wrap the training data in a Tensorflow Dataset object so that it can be efficiently fetched and fed, one batch at a time, to the model during training. The data is fetched lazily so that it doesn’t all have to be in memory at the same time. This allows us to support very large datasets.
The dataset loads the pre-processed encoded image vectors that were saved earlier. It uses the image file name to identify the saved file path.
Much of the code for this example has been taken from the Tensorflow Image Caption tutorial.
Image Caption Model with Attention
The model consists of four logical components:
- Encoder: since the image encoding has already been done by the pre-trained Inception model, the Encoder here is very simple. It consists of a Linear layer that takes the pre-encoded image features and passes them on to the Decoder.
- Sequence Decoder: this is a recurrent network built with GRUs. The captions are passed in as the input after first going through an Embedding layer.
- Attention: as the Decoder generates each word of the output sequence, the Attention module helps it to focus on the most relevant part of the image for generating that word.
- Sentence Generator: this module consists of a couple of Linear layers. It takes the output from the Decoder and produces a probability for each word from the vocabulary, for each position in the predicted sequence.
How does Attention enhance the Image Caption performance
The earliest Image Caption architectures included the other three components without Attention. Let’s first go over how that model works, and then see what is different with Attention.
At each timestep, the Decoder takes the hidden state from the previous timestep and the current input word to produce the output word for this timestep. The hidden state carries some representation of the encoded image features.
In the absence of Attention, the Decoder treats all parts of the image equally while generating the output word.
So how does Attention behave differently?
At each timestep, the Attention module takes the encoded image as input along with the Decoder’s hidden state for the previous timestep.
It produces an Attention Score that assigns a weight to each pixel of the encoded image. The higher the weight for a pixel, the more relevant it is for the word to be output at the next timestep.
For example, if the target output sequence is “A girl is eating an apple”, the girl’s pixels in the photo are highlighted when generating the word “girl”, while the apple’s pixels are highlighted for the word “apple”.
This Score is then concatenated with the input word for that timestep, and fed to the Decoder. This helps the Decoder to focus on the most relevant parts of the picture and generate the appropriate output word.
Training
We are now ready to create the training loop to train the model.
We define the functions for the optimizer and loss. We train the model for several epochs, processing a batch of data in each iteration.
There is a lot happening during training, and the flow of computations can get a little confusing. So let’s go through them step by step.
 (Image by Author)
(Image by Author)
In each epoch, the training loop performs several operations:
Setup
First, we set up the data elements that we need.
- Fetch a batch of data through the TF Dataset. This loads the image feature vectors from the saved pre-processed files and the prepared captions.
- The Encoder encodes the image feature vectors.
- The Sequence Decoder initializes its hidden state. Note that it is also possible to apply some transform on the encoded image to initialize the hidden state.
- Start off the input sequence by seeding it with only a ‘Start’ token.
Process sequence over multiple timesteps
Next, we iterate through each element of the input sequence over multiple timesteps. Let’s look at the flow for one sequence from the batch:
- The Attention Module takes the encoded image from the Encoder, and the hidden state from the Sequence Decoder and computes the weighted Attention Score.
- The input sequence is passed through the Embedding layer and then combined with the Attention Score.
- The combined input sequence is fed to the Sequence Decoder, which produces an output sequence along with a new hidden state.
- The Sentence Generator processes the output sequence and generates its predicted word probabilities.
- We now repeat this cycle for the next timestep. The Decoder’s new hidden state from this timestep is used for the next timestep. We continue doing this until an ‘End’ token is predicted or we reach the maximum length of the sequence.
- However, there is one important point to note viz. Teacher Forcing, explained below.
Teacher Forcing
- Ordinarily, during Inference when the model is fully trained, the output sequence from this timestep is used as the input sequence for the next timestep. This allows the model to predict the next word based on the previous words predicted so far.
- However, if we did that while the model was still learning during Training, any errors made by the model in predicting an output word in this timestep would be carried forward to the next timestep. The model would end up predicting the next word based on an erroneous previous word.
- Instead, since we have the ground truth captions available to us during training, we use a technique called Teacher Forcing. The correct expected word from the target caption is added to the input sequence for the next timestep rather than the model’s predicted word.
- In this way, we are helping the model by giving it a hint, so to speak, just like a teacher would.
Loss
- At each timestep, the predicted probabilities are compared with the ground truth captions to compute the loss. The loss will be used to train the network via back-propagation.
Ordinarily, as part of the training loop, we would also evaluate our metrics on the validation data. However, for the purposes of this demo, after the model is fully trained, we will go ahead with doing inference on the test data.
Inference
We extract image features from the test image using the pre-trained model. The next steps to generate a caption are very similar to what we did during training, with the following changes:
-
Greedy Search is used to predict the output by picking the word with the highest probability at each timestep.
-
Since we don’t have the ground truth caption, we don’t use Teacher Forcing. At each timestep, the predicted word is appended to the input sequence and fed back to the Decoder for the next timestep.
-
And obviously, we don’t calculate the loss and gradients, and don’t do backpropagation.

Real Caption: ‘person is rock climbing between two large rock faces’ Prediction Caption: person climbs rock to big rock endseq
Conclusion
Image Captioning is an interesting application because it combines techniques of Computer Vision and NLP, and requires working with both images and text.
We walked through an end-to-end example of Image Captions using the Encoder-Decoder architecture with Attention. We saw how Attention is used to boost the ability of the network to predict better captions. This is one of the better-performing architectures from recent years.
And finally, if you liked this article, you might also enjoy my other series on Transformers as well as Audio Deep Learning.
Let’s keep learning!