
Image Captioning is a fascinating application of deep learning that has made tremendous progress in recent years. What makes it even more interesting is that it brings together both Computer Vision and NLP.
What is Image Captioning?
It takes an image as input and produces a short textual summary describing the content of the photo.

.jpg)){kind=link}
eg. A relevant caption for this image might be “Dog standing in the grass” or “Labrador Retriever standing in the grass”.
In this article, my goal is to introduce this topic and provide an overview of the techniques and architectures that are commonly used to tackle this problem.
How does it work?
Broadly speaking Image Captioning makes use of three primary components. By the way, there are no standard names for these components - these are names that I came up with to explain their purpose.
-
Image Feature Encoder
This takes the source photo as input and produces an encoded representation of it that captures its essential features.
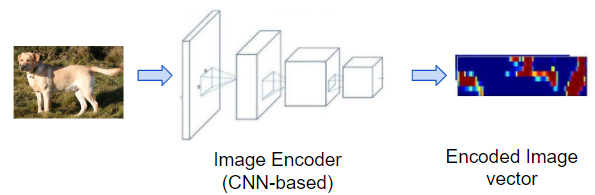 Image input to an ‘image Encoder’ and outputs an encoded vector (Image by Author)
Image input to an ‘image Encoder’ and outputs an encoded vector (Image by Author)This uses a CNN architecture and is usually done using transfer learning. We take a CNN model that was pre-trained for image classification and remove the final section which is the ‘classifier’. There are several such models like VGGNet, ResNet, and Inception.
The ‘backbone’ of this model consists of several CNN blocks which progressively extract various features from the photo, and generate a compact feature map that captures the most important elements in the picture.
eg. It starts by extracting simple geometric shapes like curves and semi-circles in the initial layers, progresses to higher-level structures such as noses, eyes, and hands, and eventually identifies elements such as faces and wheels.
 Image classification network showing the two sections and cutting off the classifier (Image by Author)
Image classification network showing the two sections and cutting off the classifier (Image by Author)In an Image Classification model, this feature map is then fed to the last stage which is the Classifier that generates the final output prediction of the class (eg. cat or car) of the primary object in the image.
When applying this model for Image Captioning, we are interested in the feature map representation of the image and do not need the classification prediction. So we keep the backbone and remove the classifier layers.
-
Sequence Decoder
This takes the encoded representation of the photo and outputs a sequence of tokens that describes the photo.
Typically this is a Recurrent Network model consisting of a stack of LSTM layers fed by an Embedding layer.
 LSTM network with initial state and sequence so far as input, output fed back (Image by Author)
LSTM network with initial state and sequence so far as input, output fed back (Image by Author)It takes the image encoded vector as its initial state and is seeded with a minimal input sequence consisting of only a ‘Start’ token. It ‘decodes’ the input image vector and outputs a sequence of tokens.
It generates this prediction in a loop, outputting one token at a time which is then fed back to the network as input for the next iteration. Therefore at each step, it takes the sequence of tokens predicted so far and generates the next token in the sequence. Finally, it outputs an ‘End’ token which completes the sequence.
-
Sentence Generator
The job of the Sentence Generator is to take the sequence of tokens and output a caption which is a sentence of words that describes the photo in the desired language.
It consists of a Linear layer followed by a Softmax. This produces a probability for every word in the target language’s vocabulary, for each position in the sequence.
This probability is the likelihood that that word occurs at that position in the sentence. We could then use Greedy Search to produce the final sentence by picking the word with the highest probability at each position.
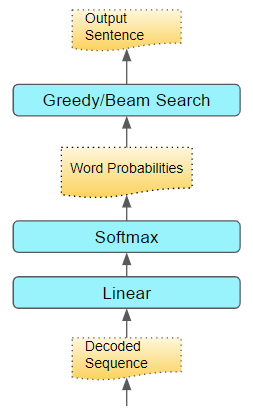 (Image by Author)
(Image by Author)That sentence is then output as the predicted caption.
Almost all Image Captioning architectures make use of this approach with the three components we’ve just seen. However, over the years many variations of this framework have evolved.
Architecture: Encoder-Decoder
Perhaps the most common deep learning architecture for Image Captioning is sometimes called the “Inject” architecture and directly connects up the Image Feature Encoder to the Sequence Decoder, followed by the Sentence Generator, as described above.
 Image Feature Encoder connected to Text Generator (Image by Author)
Image Feature Encoder connected to Text Generator (Image by Author)
Architecture: Multi-Modal
The Inject architecture was the original architecture for Image Captioning and is still very popular. However, an alternative which gets called the “Merge” architecture has been found to produce better results.
Rather than connecting the Image Encoder as the input of the Sequence Decoder sequentially, the two components operate independently of each other. In other words, we don’t mix the two modes ie. images with text.
- the CNN network processes only the image and
- the LSTM network operates only on the sequence generated so far.
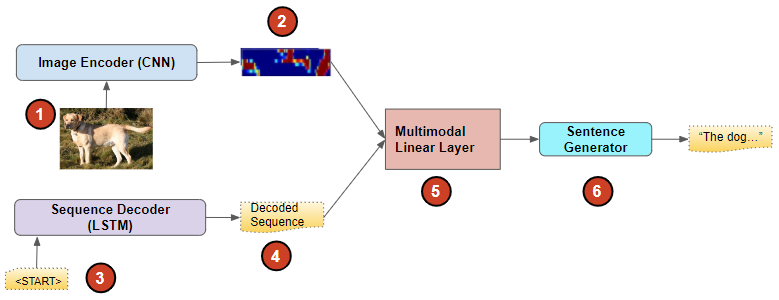 Merge architecture (Image by Author)
Merge architecture (Image by Author)
The outputs of these two networks are then combined together with a Multimodal layer (which could be a Linear and Softmax layer). It does the job of interpreting both outputs and is followed by the Sentence Generator that produces the final predicted caption.
Another advantage of this approach is that it allows us to use transfer learning not just for the Image Encoder but for the Sequence Decoder as well. We can use a pre-trained language model for the Sequence Decoder.
Many different ways of combining the outputs have been tried eg. concatenate, multiplication, and so on. The approach that usually works best is to use addition.
Architecture: Object Detection backbone
Earlier we talked about using the backbone from a pre-trained Image Classification model for the Image Encoder. This type of model is usually trained to identify a single class for the whole picture.
However, in most photos, you are likely to have multiple objects of interest. Instead of using an Image Classification backbone, why not use a pre-trained Object Detection backbone to extract features from the image?
 Object Detection backbone (Image by Author)
Object Detection backbone (Image by Author)
The Object Detection model generates bounding boxes around all the prominent objects in the scene. Not only does it label multiple objects, but it identifies their relative positions within the picture. Thus it is able to provide a richer encoded representation of the image, which can then be used by the Sequence Decoder to include a mention of all of those objects in its caption.
Architecture: Encoder-Decoder with Attention
Over the last few years, the use of Attention with NLP models has been gaining a lot of traction. It has been found to significantly improve the performance of NLP applications. As the model generates each word of the output, Attention helps it focus on the words from the input sequence that are most relevant to that output word.
It is therefore not surprising to find that Attention has also been applied to Image Captioning resulting in state-of-the-art results.
As the Sequence Decoder produces each word of the caption, Attention is used to help it concentrate on the part of the image that is most relevant to the word it is generating.
 Image Caption architecture with Attention (Image by Author)
Image Caption architecture with Attention (Image by Author)
The Attention module takes the encoded image vector along with the current output token from the LSTM. It produces a weighted Attention score. When that score is combined with the image it boosts the weight of those pixels that the LSTM should focus on while predicting the next token.
For instance, for the caption “The dog is behind the curtain”, the model focuses on the dog in the photo as it generates the word ‘dog’ and then shifts its focus to the curtain when it reaches the word ‘curtain’, as you would expect.
Architecture: Encoder-Decoder with Transformers
When talking about Attention, the current giant is undoubtedly the Transformer. It revolves around Attention at its core and does not use the Recurrent Network which has been an NLP mainstay for years. The architecture is very similar to the Encoder-Decoder with the Transformer replacing the LSTM.
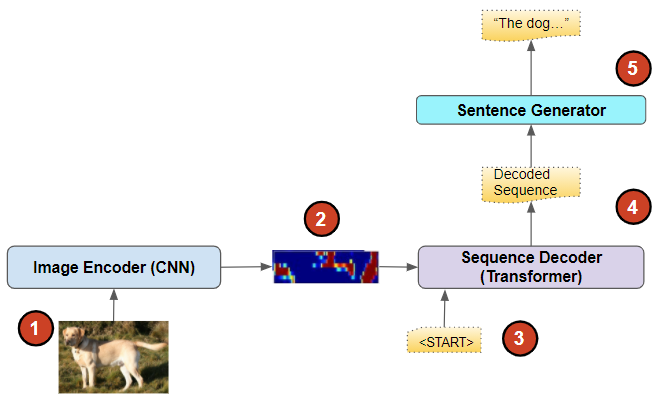 Image Caption architecture with Transformer (Image by Author)
Image Caption architecture with Transformer (Image by Author)
A few different variants of the Transformer architecture have been proposed to address the Image Captioning problem. One approach attempts to encode not just the individual objects in the photo but also their spatial relationships, as that is important in understanding the scene. For instance, knowing whether an object is under, behind, or next to another object provides a useful context in generating a caption.
Architecture: Dense Captioning
Another variant of the Object Detection approach is known as Dense Captioning. The idea is that a photo is often a rich collection of objects and activities at different positions within the picture.
Hence it can represent not just a single caption but multiple captions for different regions of the image. This model helps it capture all of the detail within the image.
 Dense Caption (Source, by permission of Prof Fei-Fei Li and Justin Johnson)
Dense Caption (Source, by permission of Prof Fei-Fei Li and Justin Johnson)
Sentence Generator with Beam Search
When the Sentence Generator produces the final caption, it can use Beam Search rather than Greedy Search that we referred to above. Rather than just picking the single word with the highest probability at each position, Beam Search chooses several words at each step, based on the combined probability of all the words in the sentence till that point.
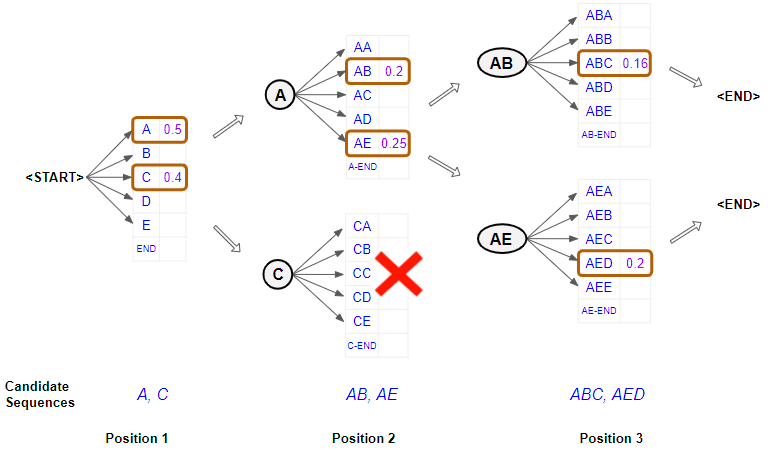 Beam Search example, with width = 2 (Image by Author)
Beam Search example, with width = 2 (Image by Author)
Beam Search is very effective and is widely used in many NLP applications. I have another article that explains its operation in detail, in a visual way. If you are interested I encourage you to take a look.
Bleu Score Metric
Once the caption is generated how do we decide how good it is? A common metric for evaluating Image Caption models is the Bleu Score. It is a popular metric for other NLP applications like translation and language models as well.
It is a simple metric and measures the number of sequential words that match between the predicted and the ground truth caption. It compares n-grams of various lengths from 1 through 4 to do this.
eg. Predicted Caption: “A dog stands on green grass” Ground Truth Caption: “The dog is standing on the grass”
Bleu Score for 1-gram = Correctly Predicted Words / Total predicted Words
The predicted words that also occur in the true caption are “dog”, “on” and “grass”, out of a total of six predicted words.
Bleu Score for 1-gram (ie. single words) = 3/6 = 0.5
Conclusion
With the advances made in Computer Vision and NLP, today’s Image Captioning models are able to produce results that almost match human performance. When you input a photograph and get back a perfect human-readable caption, it almost feels like science fiction!
We have just explored the common approaches that are used to achieve this. We are now in a good position to look under the covers and get into the details. In my next article, I will go through an example demo application step by step so we can see exactly how it works.