
Optimizers are a critical component of neural network architecture. And Schedulers are a vital part of your deep learning toolkit. During training, they play a key role in helping the network learn to make better predictions.
But what ‘knobs’ do they have to control their behavior? And how can you make the best use of them to tune hyperparameters to improve the performance of your model?
When defining your model there are a few important choices to be made - how to prepare the data, the model architecture, and the loss function. And then when you train it, you have to pick the Optimizer and optionally, a Scheduler.
Very often, we might end up simply choosing our “favorite” optimizer for most of our projects - probably SGD or Adam. We add it and forget about it because it is a single line of code. And for many simpler applications, that works just fine.
But can we do something to train our model more effectively?
An Optimizer is defined by three arguments:
- An optimization algorithm eg. SGD, RMSProp, Adam, …
- Optimization hyperparameters eg. Learning Rate, Momentum, …
- Optimization training parameters
I have another article that goes into #1 in detail. In this article we will explore how we can take advantage of #2 and #3.
In order to explain these topics, we’ll start with a quick review of the role that Optimizers play in a deep learning architecture.
This is stuff you probably already know, but please be patient, we’ll need these so we can build upon them when we get to the more interesting sections :-)
Optimization in a Neural Network
At a very high level, a neural network executes these steps over numerous iterations during training:
- A Forward pass to generate outputs based on the current parameters and the input data
- A Loss function to calculate a ‘cost’ for the gap between the current outputs and the desired target outputs
- A Backward pass to calculate the gradients of the loss relative to the parameters
- An Optimization step that uses the gradients to update the parameters so as to reduce the loss for the next iteration
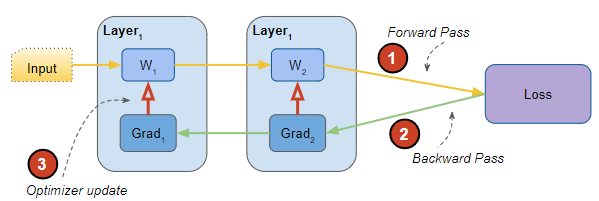 Components of a network and steps during training (Image by Author)
Components of a network and steps during training (Image by Author)
What exactly are these parameters, since they play such an important role?
Model Parameters
A network’s architecture is built of layers, each of which has some parameters. For example, a Linear or Convolutional layer has weight and bias parameters. You can also create your own custom layers and define their parameters.
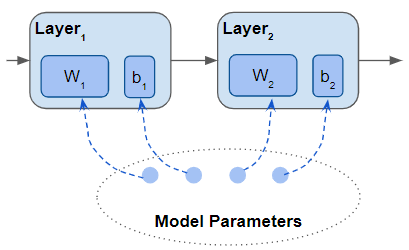 A model consisting of layers, that contain parameters. Another box called ‘Model Parameters’ that contains ‘pointers’ to all the parameters (Image by Author)
A model consisting of layers, that contain parameters. Another box called ‘Model Parameters’ that contains ‘pointers’ to all the parameters (Image by Author)
Deep Learning frameworks like Pytorch and Keras have a specific datatype to represent model parameters viz. Parameter and trainable Variable datatypes respectively.
A model parameter is a tensor. Like all tensors, they contain a matrix of numbers, but they have special behavior. They have associated gradients which are automatically computed by the framework whenever an operation is performed on a parameter in the forward pass.
Whenever a new type of layer is defined, both built-in and custom, you use this datatype to explicitly tell the framework which tensors should be treated as parameters.
Optimizer Training Parameters
So when you build the network architecture, the model’s parameters include the parameters of all the layers in that architecture.
When you create the Optimizer you tell it the set of parameters that it is responsible for updating during training. In most cases, this includes all the model’s parameters. However, there are many scenarios where you want to provide only a subset of the parameters for training.
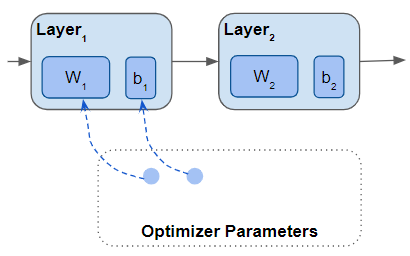 An Optimizer that contains a list of all its parameters which is a subset of the model’s parameters (Image by Author)
An Optimizer that contains a list of all its parameters which is a subset of the model’s parameters (Image by Author)
For instance, in a Generative Adversarial Network (GAN), the model has not one optimizer, but two. Each Optimizer manages only half of the parameters of the model.
When training starts, you initialize those parameters with random values. Then, after the forward and backward passes, the Optimizer goes through all the parameters it is managing, and updates each one with an updated value based on:
- The parameter’s current value
- Gradients for the parameter
- Learning Rate and other hyperparameter values
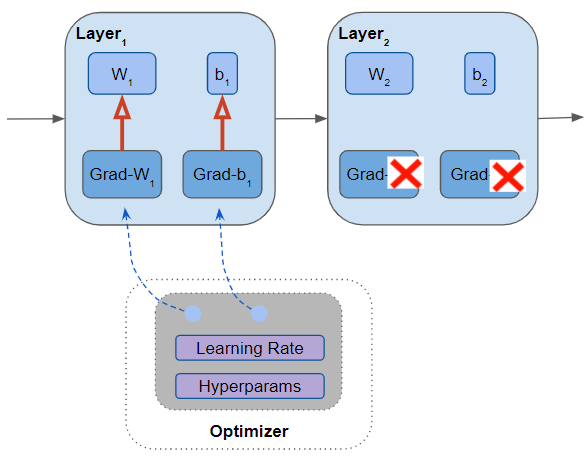 The Optimizer updates all the parameters it is managing (Image by Author)
The Optimizer updates all the parameters it is managing (Image by Author)
For instance, the update formula for the Stochastic Gradient Descent Optimizer is:
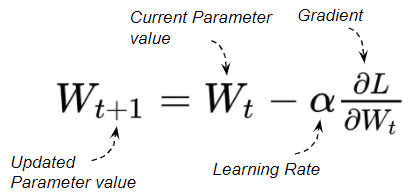 Parameter Update formula (Image by Author)
Parameter Update formula (Image by Author)
Gradients are not computed for the other model parameters that the Optimizer is not managing.
Optimization Hyperparameters
All Optimizers require a Learning Rate hyperparameter. In addition, other hyperparameters depend on the specific optimization algorithm that you are using. For instance, momentum-based algorithms require a ‘momentum’ parameter. Other hyperparameters might include ‘beta’ or ‘weight decay’.
When you create an Optimizer you provide values (or use defaults) for all the hyperparameters that the optimization algorithm requires.
The hyperparameter values you choose have a big influence on how quickly the training happens as well as the model’s performance based on your evaluation metrics. Therefore it is very important to choose these values well and to tune them for optimal results.
Since hyperparameters are so critical, neural networks give you a lot of fine-grained control over setting their values.
Broadly speaking, there are two axes that you can control. The first of these involves Parameter Groups, which we will explore next.
Model Parameter Groups
Earlier we spoke about hyperparameters as though there was a single set of values for the whole network. But what if you want to choose different hyperparameters for different layers of the network?
Parameter Groups let you do just that. You can define multiple Parameter Groups for a network, each containing a subset of the model’s layers.
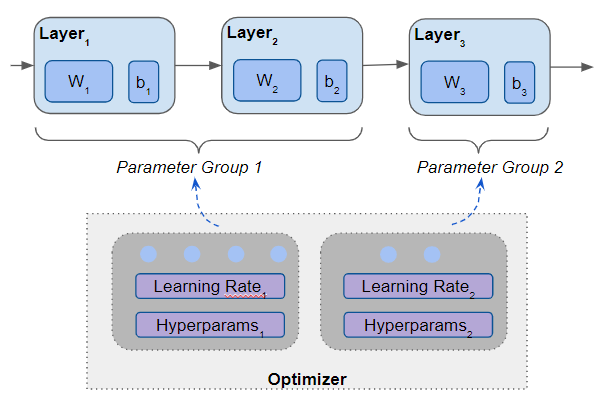 Different layers of a model can be put in different parameter groups (Image by Author)
Different layers of a model can be put in different parameter groups (Image by Author)
Now, using these you can choose different hyperparameter values for each Parameter Group. This is known as Differential Learning, because, effectively, different layers are ‘learning at different rates’.
Differential Learning Rates for Transfer Learning
A common use case where Differential Learning is applied is for Transfer Learning. Transfer Learning is a very popular technique in Computer Vision and NLP applications. Here, you take a large model that was pre-trained for, say, Image Classification with the ImageNet dataset and then repurpose it for a different and much smaller set of images from your application domain.
When you do this you want to reuse all the pre-learned model parameters and only fine-tune them for your dataset. You do not want to relearn the parameters from scratch as that is very expensive.
In such a scenario, you typically split the network into two parameter groups. The first set consists of all the early CNN layers that extract image features. The second set consists of the last few Linear layers that act as a Classifier for those features.
 Transfer Learning with an Image Classifier. The CNN layers and the Linear Classifier layers have different learning rates. (Image by Author)
Transfer Learning with an Image Classifier. The CNN layers and the Linear Classifier layers have different learning rates. (Image by Author)
Much of what the CNN layers have learned about generic image features will also apply to your application’s images. So you can train the first parameter group using a very low learning rate so that the weights change very little.
But you can use a higher learning rate for the second parameter group so that the Classifier learns to distinguish between classes for the new domain images rather than the original set.
Differential Learning with Pytorch (and Keras - custom logic)
Pytorch’s Optimizer gives us a lot of flexibility in defining parameter groups and hyperparameters tailored for each group. This makes it very convenient to do Differential Learning.
Keras does not have built-in support for parameter groups. You have to write custom logic within your custom training loop to partition the model’s parameters in this way with different hyperparameters.
We’ve just seen how to adjust hyperparameters using Parameter Groups. The second axis to exercise fine-grained control on hyperparameter tuning involves the use of Schedulers.
Schedulers for Adaptive Learning Rates
So far we’ve talked about hyperparameters as though they were fixed values decided upfront before training. What if you wanted to vary the hyperparameter values over time as training progresses?
That is where Schedulers come in. They let you decide the hyperparameter value based on the training epoch. This sometimes gets referred to as Adaptive Learning Rates.
There are standard Scheduler algorithms that use various mathematical curves to compute the hyperparameter. Pytorch and Keras have several popular built-in Schedulers such as Exponential, Cosine, and Cyclic Schedulers.
You pick the Scheduler algorithm that you want to use and specify the minimum and maximum of the range for the hyperparameter value. At the start of each training epoch, the algorithm then uses the formula, the min/max range, and the epoch number to calculate the hyperparameter value.
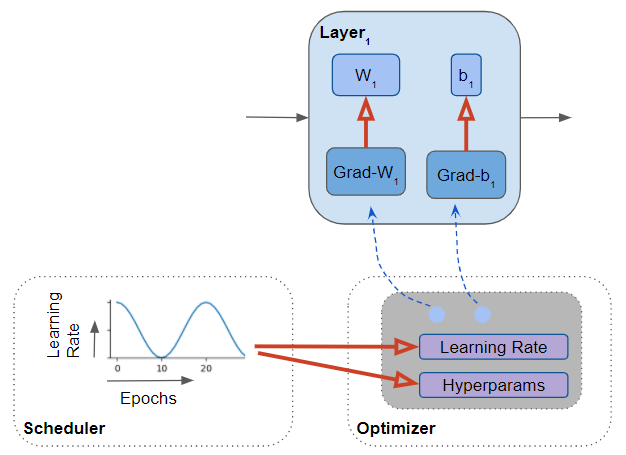 The Scheduler modifies the Learning Rate and hyperparameter values for each training epoch (Image by Author)
The Scheduler modifies the Learning Rate and hyperparameter values for each training epoch (Image by Author)
A Scheduler is considered a separate component and is an optional part of the model. If you don’t use a Scheduler the default behavior is for the hyperparameter values to be constant throughout the training process. A Scheduler works alongside the Optimizer and is not part of the Optimizer itself.
We have now seen all the different ways that hyperparameter values can be controlled during training. The simplest technique is to use a single fixed Learning Rate hyperparameter for the model. The most flexible is to vary the Learning Rate and other hyperparameters along both axes - different hyperparameter values for different layers, and simultaneously vary them over time over the course of the training cycle.
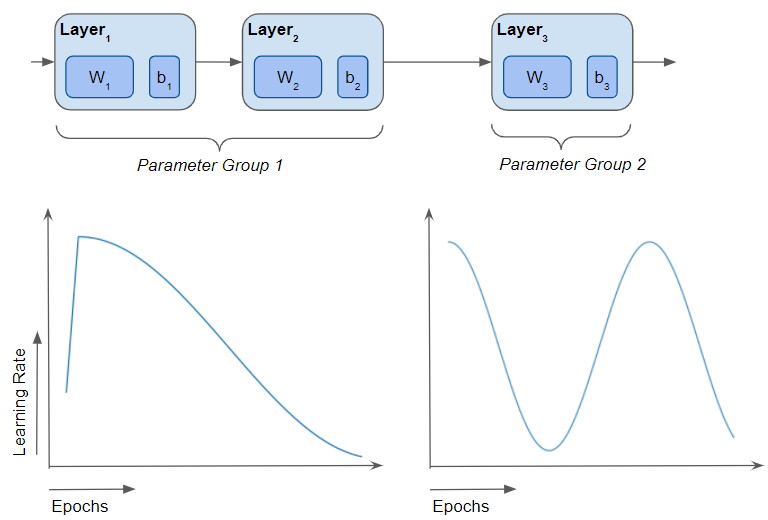 Vary training hyperparameters for different layers as well as based on the training epoch (Image by Author)
Vary training hyperparameters for different layers as well as based on the training epoch (Image by Author)
Do not confuse with Optimization Algorithms adjusting Learning Rates
A quick clarification note - you might read that some Optimization algorithms (like RMSProp) choose different learning rates for different parameters, based on the gradients of those parameters.
That is internal to those Optimization algorithms and is handled automatically by the algorithm. As the model designer, it is invisible to you. The learning rate varies based on gradients and not based on the training epoch, as is the case with Schedulers.
This happens independently of the mechanisms we’ve discussed in this article, so do not confuse the two.
Conclusion
We’ve just seen what Optimizers and Schedulers do, and the functionality they provide to allow us to enhance our models. These are handy techniques that can be used in a range of deep learning applications.
Pytorch and Keras include built-in features that make it fairly easy to adopt these techniques.
In future articles, I plan to go deeper and explore specific types of Optimizers and Schedulers and how they work.
And finally, if you liked this article, you might also enjoy my other series on Transformers, Audio Deep Learning, and Geolocation Machine Learning.